Notes on Concurrency in Python
Table of Contents
Sorry for the late post bubs. I know that this is not what was promised, but I want to make it clear that I did not slack off. Essentially what happened is that I’ve spent the last 2 weeks working on a much bigger post, which I thought I could release in just a couple of days for whatever reason, but is now looking like it might take almost a month to complete. So in the mean time, I’ll be peppering this timeline with posts about random stuff that I’m learning in the process of building said project that would be too off-topic to include in the mega post itself. Enough yapping though, let’s get down to business.
The topic today is concurrency/parallelism and how we can implement it in python for our projects. I’ll start off by explaining what exactly this means:
Concurrency vs Parallelism⌗
- Concurrency:
- At least two tasks happening at the same time, but not necessarily executing simultaneously
- Can be obtained on a single core CPU via task-switching using a mechanism known as multitasking. In this case, only one task is actually running at any given instant.
- Parallelism:
- Tasks are both concurrent and executing at the same time
- Requires at least two CPU cores
- Parallelism implies concurrency, but not vice versa
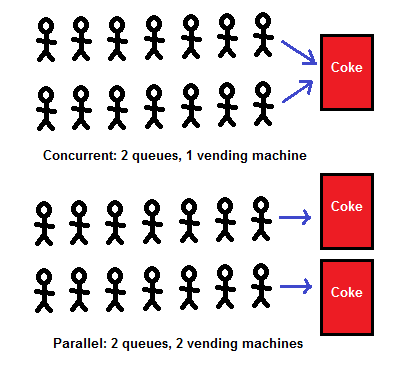
Seems simple enough! But in order to fully understand how these concepts can be implemented in python, we will first need a primer on the
Python Execution Model⌗
The python execution workflow goes like this
- Python source code
- Bytecode
- Python Virtual Machine (PVM)
- Executable
- Hardware

Bytecode⌗
- Intermediate representation of Python code
- Platform-agnostic, allowing for cross-platform compatibility
- Each python statement is converted into a group of bytecode instructions
- Looks like this
from dis import dis
def add(a,b):
return a + b
print(dis(add))
OUTPUT: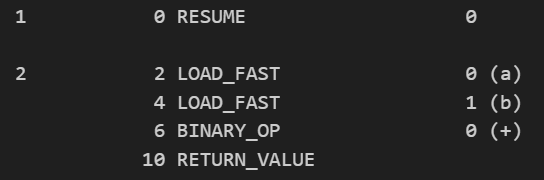
Python Virtual Machine (PVM)⌗
- Converts bytecode into machine code
- Equipped with an interpreter to execute the bytecode
- Typically assigns work to only one CPU due to the Global Interpreter Lock (more on this later)
- Looks like this (shocking)

Python vs C++ vs Java⌗
Now that we are familiar with the execution model of Python, we need a benchmark to compare it to. C++ and Java make for great comparisons. The models of these languages differ slightly, and unfortunately this slight difference has a huge impact on execution speeds.
Python: Source code → Bytecode → PVM → Executable → Hardware
- Flexible but harder to optimize than C and Java
- Cannot utilize cache as effectively as Java
C++: Source code → Executable → Hardware
- Directly compiled to machine code, fastest of the three (not even a contest)
Java: Source code → Bytecode → JVM → Executable → Hardware
- Uses Just-In-Time (JIT) compilation
- Can utilize cache for optimizations
As a python enjoyer I am sad to admit that C++ absolutely mogs python when it comes to low latency applications. But that’s why claude exists - to transform all my unoptimized python slop into kino C++ nanosecond inference code.
Global Interpreter Lock (GIL): The Great Limiter⌗
Every performance-related limitation in python comes down to the global interpreter lock. It’s a key concept to understand if you want to know why exactly python isn’t the best for performance critical operations. Cliffs notes are as follows:
- CPython, the reference implementation for python, is not natively thread safe
- What this means is that if multiple threads share a variable and attempt to modify it, the result is non-deterministic, and causes a state known as race condition
- Example of a race condition: Consider two threads incrementing a shared counter. If not properly managed, they might read the same initial value, increment it, and write back, effectively losing one increment.
- While threads can run concurrently on different cores, the GIL ensures that only one of them can run Python bytecode at a time to prevent race conditions, thus ensuring thread safety
- Unfortunately, this makes multithreading for CPU-bound tasks close to impossible in CPython, regardless of the availability of multiple cores
If this doesn’t make much sense right now, keep reading, it should become clearer.
Workarounds for GIL⌗
Before we get into understanding how we can bypass the limitations of GIL, there is some prerequisite knowledge that we must know.
I/O vs CPU Bound Work⌗
In general, an application’s work can be divided into I/O and CPU bound (bound means limiting factor) work:
- I/O operations involve a computer’s input and output devices, such as keyboard, hard drive and network cards
- CPU operations involve the central processing unit, and consists of work such as mathematical computation
Processes vs Threads⌗
| Processes | Threads |
|---|---|
| Independent execution units with their own memory space | Lightweight execution units within a process |
| Isolated from other processes | Share memory with the parent process |
| Can run in parallel on multi-core systems | Multiple threads in a process can run concurrently |
| Heavier weight, more resource-intensive | Lighter weight, less resource-intensive |
| Used for CPU-intensive tasks, parallel execution across multiple cores/machines | Used for I/O-bound tasks, concurrent operations within an application |
| Used for running independent programs | Used for concurrent operations within a program |
Additional points:
- Every process has at least one thread known as the main thread. The other threads created from the main thread are known as worker threads.
- One can think of threads as lightweight processes, with a different memory profile
- The entry into any Python application begins with a process and its main thread
That’s it for the prerequisites!
Multithreading & Multiprocessing⌗
Multithreading and multiprocessing are the python implementations of concurrency and parallelism which allow us to get around the limitations of the GIL:
Multithreading for I/O-bound tasks⌗
Key Concept: I/O operations make lower level system calls in the OS that are outside of the Python runtime
- GIL is released from a thread when an I/O task is happening since we are not working directly with Python objects
- In this period, the GIL is assigned to another thread that requires it
- GIL is reacquired by the original thread when data is translated back into Python objects
Multiprocessing for CPU-bound tasks⌗
Key Concept: Allows utilization of multiple CPU cores
- Creates multiple separate Python processes
- These processes can be run in parallel because each process has its own interpreter (PVM and GIL) that executes the instructions allocated to it
- Only one process can execute (whether its running, ready, blocked, etc.) on a single core at any given instant
- OS scheduler manages time-sharing of cores among processes
Multithreading vs Multiprocessing⌗
| Multithreading | Multiprocessing |
|---|---|
| Works by creating multiple threads within a single process, sharing the same memory space | Works by creating multiple independent processes, each with its own memory space |
| Threads share the same memory space and resources | Each process has its own memory space and resources |
| Concurrency, but not true parallelism | True parallelism |
| Lighter-weight than multiprocessing | Higher overhead* compared to multithreading |
| Better for I/O-bound tasks because when a thread is waiting for I/O, it releases the GIL, allowing other threads to execute | Generally less efficient for I/O-bound tasks due to higher overhead |
| Good for operations that spend significant time waiting for input/output to complete like downloading stock market data, running database queries, and file operations | Good for CPU-intensive tasks like number crunching and data processing |
| Very limited use for CPU-bound tasks due to GIL | Useful for CPU-bound tasks because it can utilize multiple CPU cores simultaneously |
*Multiprocessing in Python works by allowing a single program to control multiple PVMs. The overhead comes from the allocation of new memory blocks and resources to create new PVMs.
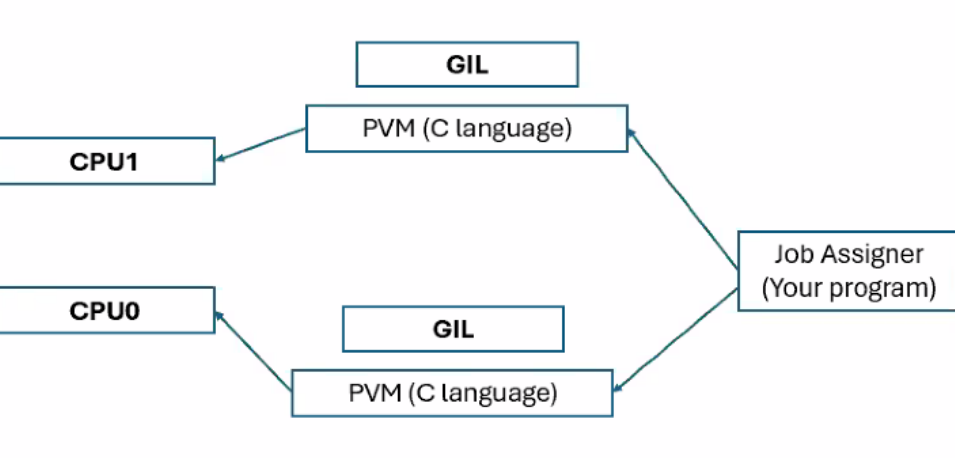
Python vs C++ vs Java Revisited⌗
Does this mean that Python can actually match up to C++ and Java? Stop asking, the answer is still no (T_T). Let’s look at this again, this time through the lens of multithreading/multiprocessing:
- With multiprocessing, Python can utilize multiple cores effectively, similar to C and Java, and thus achieve performance comparable to these languages on very CPU-intensive tasks where the computation time outweighs the process creation and communication overhead.
- However, C and Java can multithread CPU-bound tasks (unlike Python which can only multithread I/O-bound tasks). As a consequence, for shorter-running tasks or those requiring frequent communication between parallel units, the overhead of multiprocessing will result in lower performance compared to multithreaded solutions in C or Java.
Numpy and Alternative Python Implementations⌗
Another way to get around the GIL is by using numpy or alternative python implementations:
- NumPy is implemented in C and can thus bypass the GIL, allowing for better performance
- Interops is what allows Python to interface with compilers of other languages, which enables libraries like NumPy to exist
- Some alternative implementations (e.g., Jython, IronPython) don’t have a GIL, potentially allowing multi-threading of CPU-bound tasks
but this comes with its own set of caveats
- Numpy can only be used for very specific number crunching purposes
- Alternative implementations suffer from compatibility issues and are not well documented
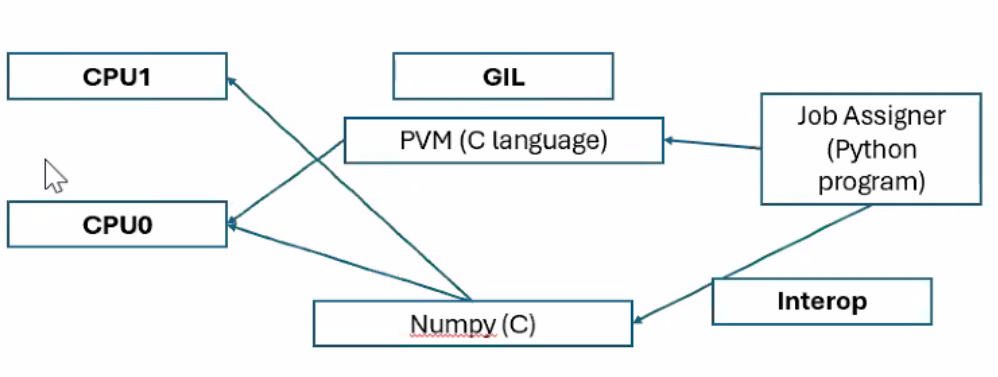
Implementing Concurrency in Python (Code)⌗
Finally we can get to the meat of it. Even though it may not match up to C++ in terms of speed, python has a lot of things to offer us beyond speed (specially for machine learning applications). Even so, this doesn’t mean that we should give up on reducing latency altogether! As we have learned, multithreading/multiprocessing are great ways to improve execution performance. In this section, I’ll go over a couple of libraries that can provide this functionality in python and accompany them with minimum viable examples to show how we can use them to optimize our own apps. But before that, a real quick intro on the different types of multitasking. I swear this is not stalling, knowing this is pretty much necessary to understand the nuance between library choices.
Preemptive vs Cooperative Multitasking⌗
CPU multitasking falls under two types.
- Preemptive multitasking: the OS decides how and when to switch between different tasks via time slicing. When the OS switches between running threads or processes, a context switch is said to be involved, and the OS needs to save the state of the running process/thread in order to continue later.
- Cooperative multitasking: the running process decides to give up CPU time via explicitly earmarked regions in the code.
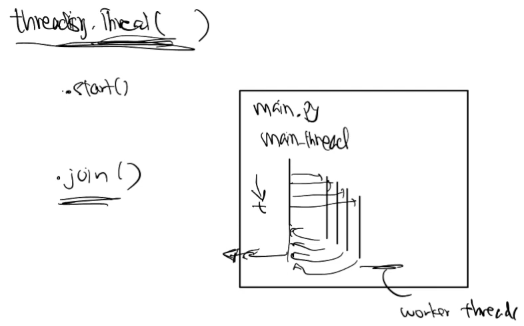
Multithreading with threading⌗
threading uses preemptive multitasking to enable multithreading in Python.
Code⌗
import threading # Import the threading module
def thread_function(name):
print(f"Thread {name} is running") # This runs in a worker thread
# Main thread creates and starts worker threads
threads = [threading.Thread(target=thread_function, args=(f"T{i}",)) for i in range(3)] # Create 3 Thread objects
[thread.start() for thread in threads] # Main thread starts each worker thread
# Main thread waits for all worker threads to complete
[thread.join() for thread in threads] # Main thread blocks until each worker thread finishes
print("All threads completed") # Main thread continues after all workers are done
In English:
- Main thread starts with script execution.
threading.Thread()creates a Thread object (blueprint), not a running threadthread.start()creates and begins execution of a new worker threadthread.join()makes the main thread wait for the worker thread to finish
The fact that the main thread must join() each worker thread sequentially, blocking until each completes, is what makes this code synchronous. This synchronicity is what makes the code simple to understand due to the predictable execution order, but also makes it less efficient for I/O-bound tasks. More on this later.
Multiprocessing with multiprocessing⌗
multiprocessing enables true parallelism in Python. I’d wager that this is not as useful as threading since most of our CPU-intensive tasks will be number crunching, which is what numpy is for.
Code⌗
import multiprocessing # Import the multiprocessing module
def process_function(name):
print(f"Process {name} is running") # This runs in a separate process
if __name__ == "__main__": # Ensures this runs only when script is executed directly
# Main process creates and starts worker processes
processes = [multiprocessing.Process(target=process_function, args=(f"P{i}",)) for i in range(3)] # Create 3 Process objects
[process.start() for process in processes] # Main process starts each worker process
# Main process waits for all worker processes to complete
[process.join() for process in processes] # Main process blocks until each worker process finishes
print("All processes completed") # Main process continues after all workers are done
In English:
- Main process starts with script execution
multiprocessing.Process()creates a Process object (blueprint), not a running processprocess.start()creates and begins execution of a new worker processprocess.join()makes the main process wait for the worker process to finish
Asynchronous Programming with asyncio⌗
Time for a wild card entry. Asyncio is a library that also provides a framework for concurrency in Python. However, it doesn’t do this through multithreading or multiprocessing. Instead, it employs asynchronous programming.
What exactly does this entail? For one, asyncio uses coroutines and an event loop to achieve concurrency, rather than using threads or processes. This is known as a cooperative multitasking model, where tasks voluntarily yield control when they’re waiting for something (like I/O operations) rather than being preemptively interrupted.
Comparison with threading⌗
| Aspect | Asyncio | Threading |
|---|---|---|
| Concurrency Model | Cooperative multitasking (tasks yield control voluntarily) | Preemptive multitasking (OS schedules threads) |
| Execution | Single-threaded, runs on one CPU core | Multi-threaded, can utilize multiple CPU cores |
| Resource Usage | Typically lower memory footprint | Higher memory usage due to separate thread stacks |
| Scalability | Highly scalable due to non-reliance on OS | Limited due to context switch overhead |
| Complexity | Harder to reason about execution flow due to complex code structure | Straightforward execution order, so code is easier to understand |
Key Concepts⌗
Asynchronous Programming: Asynchronous programming allows parts of a program to run independently of the main program flow.
Coroutines: Coroutines are the building blocks of asyncio-based code. They are special functions that can be paused and resumed, allowing other code to run in the meantime. Coroutines are defined using the async def syntax and are called using the await keyword.
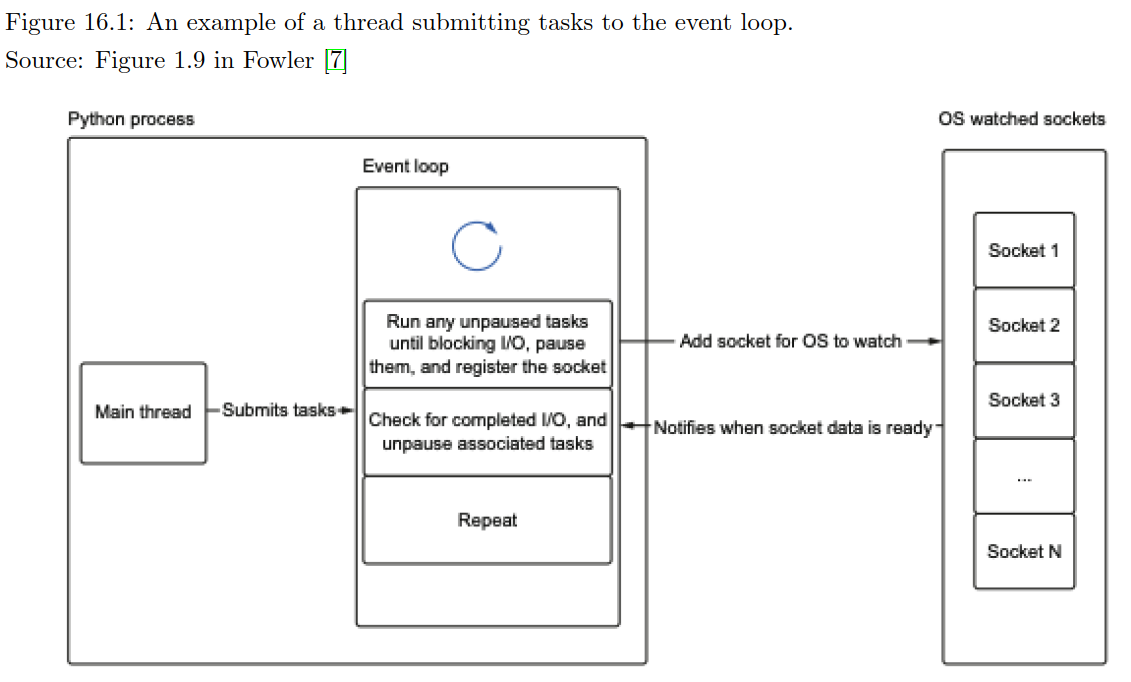
Event Loop: The event loop is at the core of every asyncio application. It runs asynchronous tasks and callbacks, performs network I/O operations, and manages subprocesses. The event loop is responsible for scheduling and running coroutines concurrently.
Sockets: Low-level abstractions that provide endpoints for data transfer between applications over a network. Things to note:
- By default, sockets are blocking. when reading or writing, the application will wait until the operation is complete.
- However, sockets can be set to a non-blocking mode. Operations return immediately, even if not complete. The catch is that your application needs to keep checking if the operation has been completed.
- Different operating systems have different ways of notifying programs about socket events. Sounds complex, and it is! Thankfully, asyncio abstracts away these OS-specific details, allowing us to remain mostly ignorant about the underlying mechanisms.
- This non-blocking approach is what lets asyncio efficiently manage many network connections at once, without getting stuck waiting on any single operation.
Tasks: Wrappers around coroutines that are scheduled and managed by the event loop.
Event Loop Workflow⌗
- An event loop is instantiated with an empty queue of tasks
- The loop iterates continuously, checking for events and tasks to run
- When a task is selected, the loop runs its coroutine
- If the coroutine hits an I/O operation, it’s suspended
- The loop makes necessary system calls for the I/O operation
- It also sets up notifications for the operation’s progress
- The suspended task is put back in the queue
- The loop moves on to check for and run other tasks
- Each iteration also checks for completed tasks
- This process repeats, allowing concurrent execution
- When all tasks are complete, the loop exits
Code⌗
import asyncio
async def coroutine1():
print("Task 1 started")
# Simulate an I/O operation that takes 2 seconds
# During this time, the event loop can run other tasks
await asyncio.sleep(2)
print("Task 1 finished")
async def coroutine2():
print("Task 2 started")
# Simulate an I/O operation that takes 1 second
await asyncio.sleep(1)
print("Task 2 finished")
async def main():
# Create task objects from coroutines
# These tasks are scheduled to run on the event loop
task1 = asyncio.create_task(coroutine1())
task2 = asyncio.create_task(coroutine2())
# Wait for both tasks to complete
# The 'await' keyword allows the event loop to run other tasks
# while waiting for these tasks to finish
await task1
await task2
# Run the event loop with the main coroutine
# asyncio.run() creates a new event loop and runs the main coroutine until it's complete
asyncio.run(main())
In English:
- Start task1, encounter the sleep, and switch to task2
- Start task2, encounter the sleep
- After 1 second, resume and finish task2
- After another 1 second (2 seconds total), resume and finish task1
- Return control to main(), which completes
- Close the event loop
Closing Notes⌗
This has been a fun exercise! Undoubtedly, understanding concurrency has given us a greater understanding of production systems. Before I close here, I would like to mention HangukQuant’s great PDF on the topic which served as the main reference for this post. Highly recommend going through it if you have time. That’s about it!
Alright, see you in the next one :))